
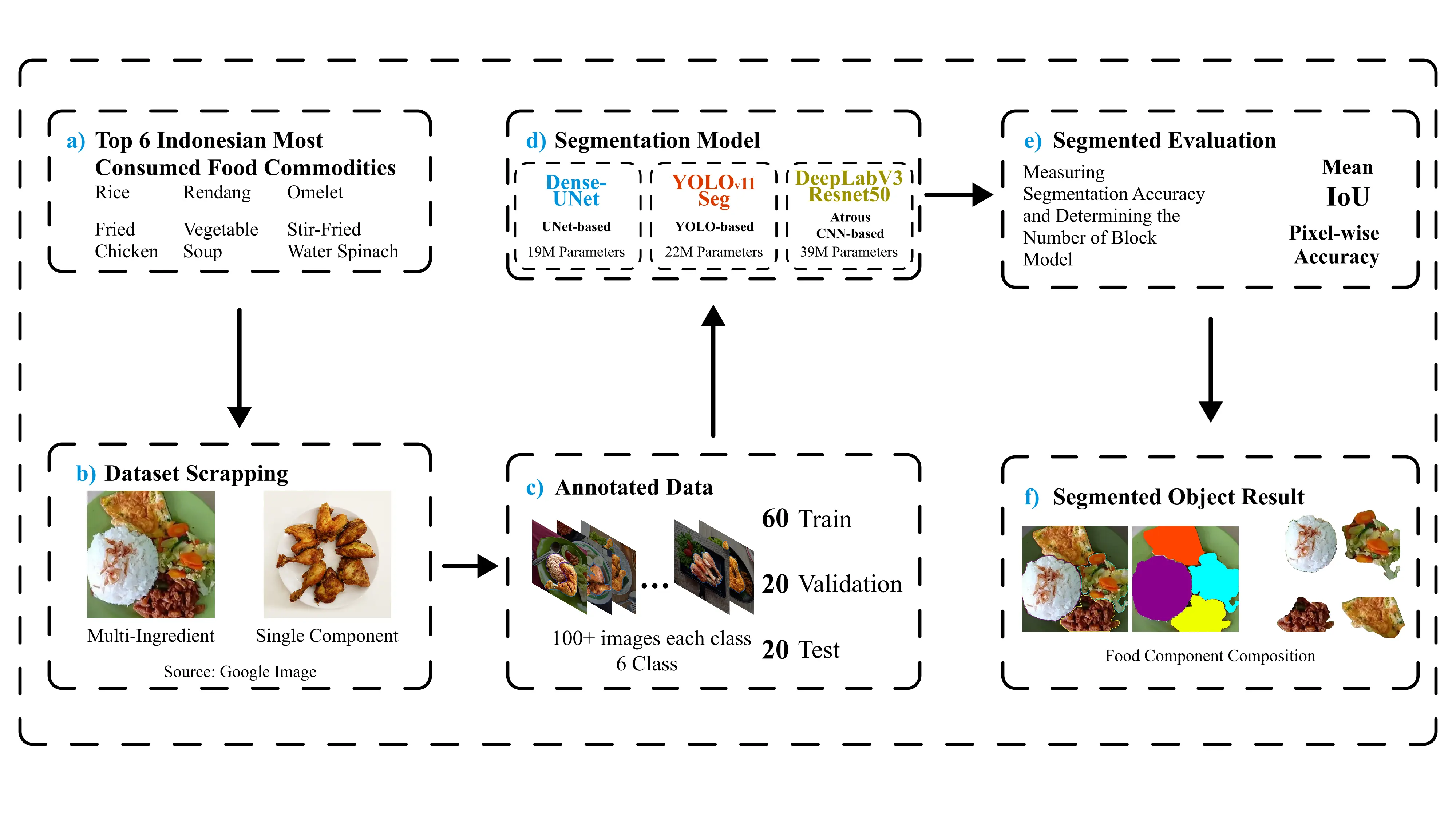

To address the lack of efficient AI tools for local cuisine , I developed a lightweight DenseNet-based U-Net (Dense-UNet) for semantic segmentation of Indonesian food. I curated a custom dataset of complex dishes to train the model, prioritizing a balance between high accuracy and computational speed suitable for real-world deployment. The architecture was successfully validated against industry standards DeepLabV3+ and YOLOv11-Seg, proving its effectiveness for resource-constrained environments.
The project covers the full pipeline, from dataset collection and annotation to model design, training, evaluation, and comparative analysis.
| Aspect | Description |
|---|---|
| Task | Semantic Segmentation |
| Domain | Indonesian Food Images |
| Models | Dense-UNet, DeepLabV3+, YOLOv11-Seg |
| Metrics | mIoU, Pixel Accuracy |
| Focus | Accuracy-Efficiency Trade-off |
To address the lack of representative data for local cuisine, I developed a custom dataset containing approximately 600 manually annotated images , covering six common Indonesian dishes. This data was rigorously curated and labeled using Roboflow. The dataset is designed to evaluate model robustness in authentic environments while maintaining the specific visual complexity of the real world:
Overlapping Ingredients : Dense arrangement of food items where ingredients frequently obscure one another.
Inconsistent Lighting : Varied illumination levels typical of non-studio, real-world photography.
Texture Ambiguity : High visual similarity between distinct food components that complicates boundary detection.





The food dataset used for training segmentation models in this project.
Prioritizing implementation on devices with limited resources, I designed a specialized architecture that emphasizes computational efficiency over the raw cost of transformer-based models. I used a modified U-Net framework as the main foundation, optimizing it specifically to handle the complex textures and spatial details of Indonesian cuisine through three strategic technical integrations, as follows:
DenseNet Encoder : Selected to maximize feature reuse and improve gradient flow, allowing the model to learn fine-grained food textures with fewer parameters.
ASPP (Atrous Spatial Pyramid Pooling) : Integrated at the bottleneck to capture multi-scale context, ensuring the model understands global object relationships without significantly increasing model size.
Attention Mechanisms : Embedded within skip connections to refine feature fusion, dynamically emphasizing relevant food boundaries while suppressing background noise during decoding.
The architecture prioritizes parameter efficiency and deployability over marginal accuracy gains.
To ensure a fair and consistent benchmark across all models, the following training configuration was strictly maintained:
| Component | Configuration Details |
|---|---|
| Input Resolution | 640 × 640 pixels |
| Data Augmentation | On-the-fly random flips, rotations, and brightness adjustments |
| Splitting Strategy | Stratified sampling (to maintain class balance across Train/Val/Test) |
| Optimizer | Adam with scheduled learning rate decay |
| Primary Metric | Validation Mean Intersection over Union (mIoU) |
All baseline models were trained from scratch on the same dataset to avoid bias from external pretraining.
Quantitative evaluation indicates that Dense-UNet achieves competitive segmentation performance in terms of mean Intersection over Union (mIoU) while using substantially fewer parameters than larger baseline models . Although DeepLabV3+ attains the highest mIoU on the curated dataset, the proposed Dense-UNet demonstrates comparable segmentation quality despite operating with roughly half the number of learnable parameters.
Qualitative inspection further supports these findings. Dense-UNet produces coherent segmentation masks on complex Indonesian dishes with overlapping ingredients, maintaining stable boundaries across visually dense regions. In comparison, instance-based approaches such as YOLOv11-Seg occasionally exhibit fragmented contours in closely packed food components, highlighting the suitability of encoder-decoder architectures for this task.
| Model | Accuracy | Efficiency |
|---|---|---|
| DeepLabV3+ | Highest | Low |
| YOLOv11-Seg | Competitive | High |
| Dense U-Net | Competitive | Very High |
Detailed quantitative metrics (mIoU, inference speed, parameter count) are available below.
| Model | mIoU | Params (M) |
|---|---|---|
| DeepLabV3+ | 0.93 | 39 |
| YOLOv11-Seg | 0.74 | 22 |
| Dense U-Net | 0.81 | 19 |
The results highlight a clear trade-off between architectural complexity and deployment practicality. While larger models offer marginal accuracy improvements, they introduce significant computational overhead that limits real-world usability.
Dense-UNet demonstrates that carefully designed convolutional architectures can still compete with modern baselines when optimized for efficiency . However, performance degradation is observed on translucent ingredients, indicating limitations in handling low-contrast areas.
Trade-off Table:
| Aspect | Observation |
|---|---|
| Accuracy | Slightly below DeepLabV3+ |
| Efficiency | Significantly better |
| Robustness | Strong on textured foods |
| Weakness | Translucent areas |
Lightweight architectures still struggle with low-contrast or translucent food components.
Given more time and resources, future improvements would focus on addressing translucent ingredient segmentation and improving generalization across broader food categories. Planned enhancements include:
- Expanding the dataset
- Exploring hybrid attention mechanisms for low-contrast areas
- Model distillation for mobile deployment
- Integrating nutrient estimation on top of segmentation outputs